Эта обзорная статья, в которой я постараюсь избегать подробностей и ненужных деталей, предназначена она в основном для новичков.
Есть два подхода при построении современных суперкомпьютеров — системы с общей памятью и так называемые кластеры. Каждый подход не исключает другого, у каждого подхода есть свои достоиинства и недостатки. Плюс систем с общей памятью — универсальность модели параллельного ПО, не требующей какого либо дополнительного кода, или не требующей значительных изменений кода. Плюс кластерных систем — отказоустойчивость и более лучшая масштабируемость. Системы с общей памятью плохо масштабируются при росте числа вычислительных процессоров, кластеры же масштабируются плохо из-за возрастающей сложности сети при добавлении узлов, но это происходит значительно позднее, когда число процессоров измеряется сотнями и даже тысячами. Рассмотрим подробнее оба этих подхода
Система с общей памятью, или многопоцессорная система. Возможны два варианта построения такой системы:
а) Все процессоры имеют равноправный доступ к памяти. Память равноудалена от всех процессоров. Это так называемые SMP (Symmetric Multi-Processing), симметричные процессорные системы.
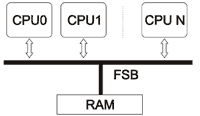
Как видно из иллюстрации все процессоры связаны с общей памяти через FSB (Front Side Bus). Эта же шина и является узким местом такой архитектуры, поскольку ее пропускная способность должна удовлетворять запросы каждого процессора, даже если они поступают одновременно.
б) Каждый процессор имеет свою локальную память и более затратный доступ к памяти других процессоров. Это NUMA системы, или системы с неодинаковым доступом к памяти.
В NUMA cистемах каждый процессор имеет локальную память и при правильной привязке процессов к процессорам всегда используется «ближняя» память. Доступ же в дальную память, с соответствующим пенальти происходит только при коммуникации процессов. Если привязки процессов нет, то в результате так называемой «миграции», процесс может быть запущен на другом процессоре и работать со своими данными из дальней памяти.
Общая проблема NUMA систем — большое количество линков, возрастающее при увеличении числа процессоров. Для двухпроцессорной NUMA cистемы достаточно одного линка между процессорами:
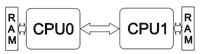
При добавлении процессоров получается более сложная организация:
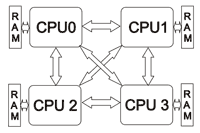
Можете представить, что будет для системы с восемью процессорами. Это будет похоже на паутину 🙂 С давних времен сложилось так что Intel продвигает SMP системы на рынке, а AMD — NUMA. В случае Intel-a связь между процессорами сделана на основе QPI, соответственно для AMD это HyperTransport. Фактически при использовании SMP систем каких-то дополнительных сложностей нет. Все процессоры равны и даже миграция (теряется кэш) не сильно влияет на производительность. В случае NUMA уже порой приходится задумываться о привязке процессов/потоков к определенному процессору (или к любому но намертво).
Следущий шаг усложнения кластеры. Кластер — это набор узлов, обединенных сетью. Узлы могут быть одинаковые (гомогенные кластеры) или разные (гетерогенные кластеры). Обычно кластер имеет как минимум одну головную ноду (head node) и отдельные узлы для файловой системы. Собственно каждый узел (computation node, нода) внутри может быть небольшой SMP или NUMA системой. В этом нет ничего страшного, практически так стоятся все современные суперкомпьютеры, и есть тенденция к увеличению количества процессоров в одной ноде. Между собой ноды связаны сетью, применяется как Gigabit Ethernet (GigE) или более быстрые сети Infiniband (Mellanox, QLogic), Myrinet или другие пропиетарные интерконнекты и сети. Основные два условия к ПО кластера — обеспечить общий диск между узлами (shared space) и службу удаленного запуска приложений (это может быть telnet, ssh, rshell и т.п). От размера кластера главным образом зависит то, каким будет топология его сети. Небольшие по размеру кластера могут строиться на одном-двух свичах, а для связывания больших кластеров свичи объединяются в несколько уровней. Например, простой вариант, когда количество узловменьше или равно количеству портов у свича:
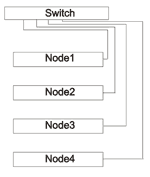
Так строится одна стойка кластера. На рисунке показана только вычислительная сеть. В случае объединения двух стоек, можно воспользоваться одним из портов свича для создания связи свич-свич.
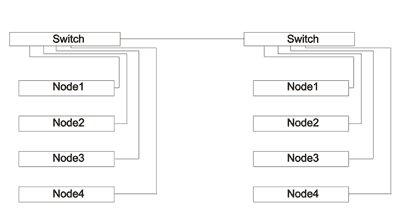
При таком варианте обмен между стойками проходит через одину пару портов, что может приводить к замедлению коммуникаций, особенно коллективных.
Дальнейший рост сложности сети приводит к многоуровневым схемам построения свичей:
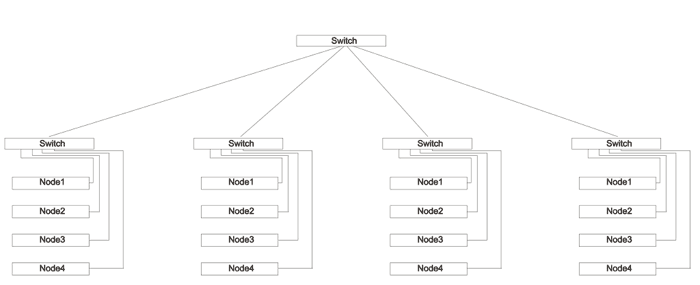
Обычно для крупных систем хватает два уровня. Свичи делятся на Leaf и Spine. Узлы подключаются только к Leaf. Все Leaf связаны между собой через Spine. Вот пример топологии 256-нодового кластера с Infiniband свичем CISCO:
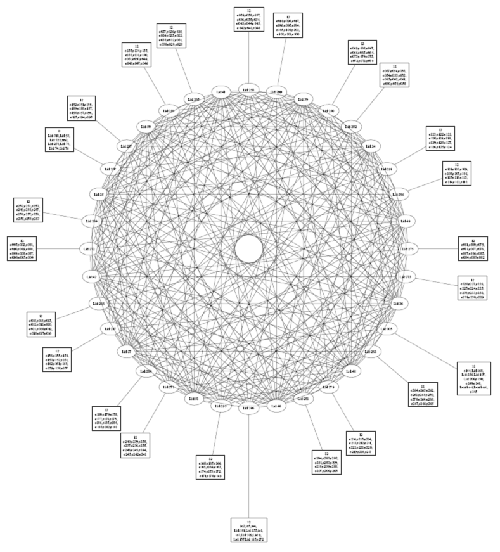
Квадратами обозначаются ноды (по 12 шт в одном квадрате). Эти 12 шт подключены к одному листу (Leaf-у), который в свою очередь соединяется с 12-ю Spine. Такой кластер обеспечивает запуск задачи одновременно на 2048 ядрах или 256 нодах при довольно интенсивном межузловом обмене.
Теперь немного о том, как это выглядит. Типичная конструкция, кластер размещается в трех стойках:

Свич установлен в дальней стойке сверху. Сверху вниз стойка заполнена нодами. Внизу каждой стойки установлен источник бесперебойного питания. В центральной части установлена login-node и скорее всего синего цвета ноды файловой системы.
Так выглядит серверная комната в яндексе:

Это скорее всего кластер кластеров установленный в одном помещении.
очень познавательная статья
спасибо
а так дизайн сайта слишком темный
чуток раздражает
seriously interesteed in openmp.
can you contact me?
where i can find admin?
Спасибо. Освежил память и узнал кое что нового (: